
Writen by
Digital Operational Resilience Act
Article


What is DORA?
The Digital Operational Resilience Act (DORA) is a legislative proposal by the European Commission to ensure the digital operational resilience of the financial sector. It aims to establish a comprehensive framework for the management of ICT risks and incidents, including cybersecurity, data protection, and operational risks. The proposal covers a wide range of financial entities, including credit institutions, investment firms, payment institutions, and insurance companies, and sets out requirements for governance, risk management, incident reporting, and oversight by competent authorities.
Overview
There is a little recap schema of the DORA proposal:
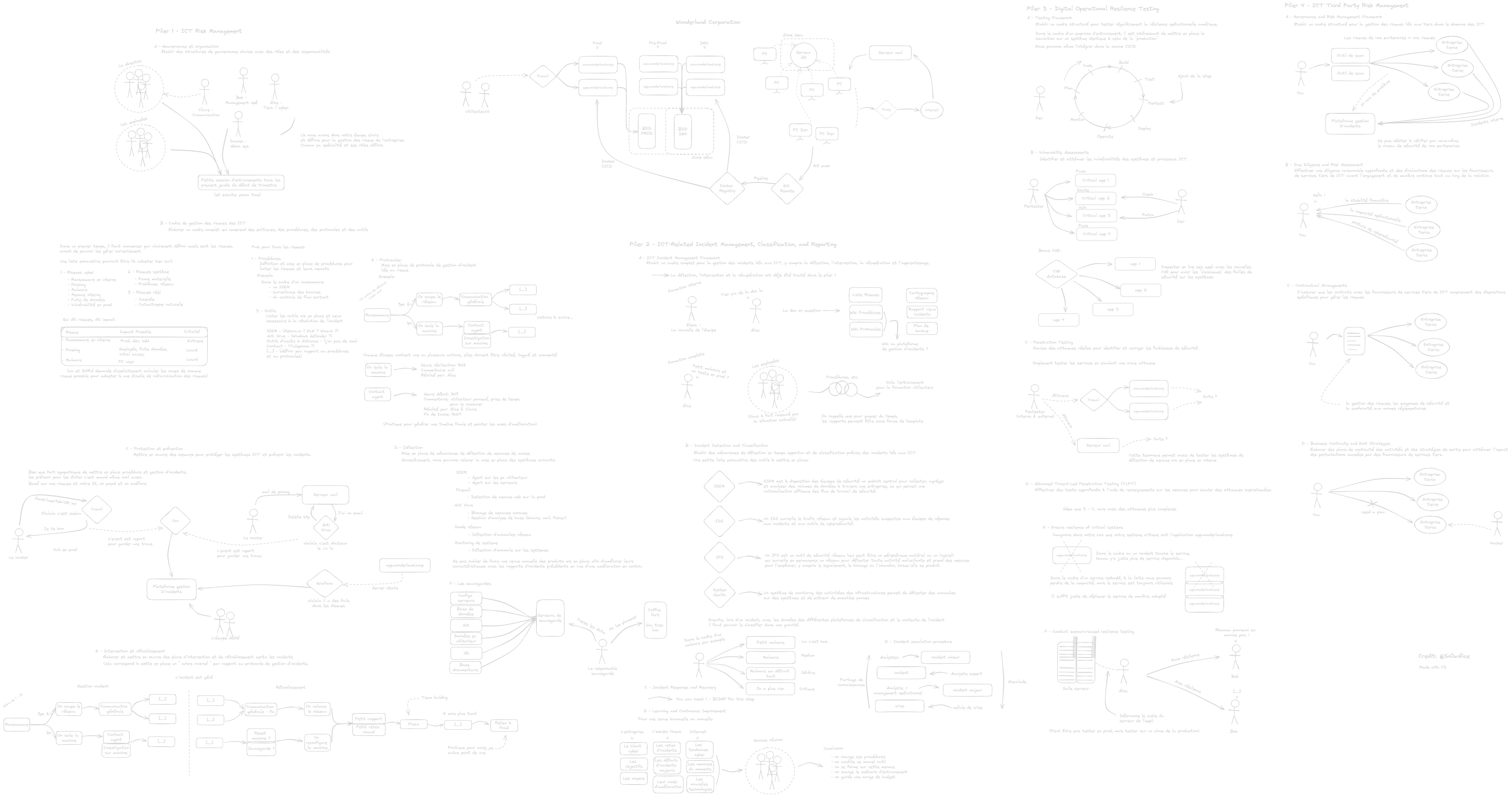 (All other resources, like a bigger scheme, are available here)
(All other resources, like a bigger scheme, are available here)
Summary
- Short Introduction
- The objective of DORA
- Pillar 1 - ICT Risk Management
- Pillar 2 - ICT-Related Incident Management, Classification, and Reporting
- Pillar 3 - Digital Operation Resilience Testing
Short Introduction
The Digital Operational Resilience Act (DORA) is a legislative proposal by the European Commission to ensure the digital operational resilience of the financial sector. It aims to establish a comprehensive framework for the management of ICT risks and incidents, including cybersecurity, data protection, and operational risks. The proposal covers a wide range of financial entities, including credit institutions, investment firms, payment institutions, and insurance companies, and sets out requirements for governance, risk management, incident reporting, and oversight by competent authorities.
The proposal is part of the European Commission's broader efforts to strengthen the EU's digital single market and ensure the stability and integrity of the financial system. It builds on existing EU legislation, such as the General Data Protection Regulation (GDPR) and the Network and Information Security Directive (NISD), and aims to address the growing challenges posed by digitalization and cyber threats.
The proposal is currently under review by the European Parliament and the Council of the European Union, and is expected to be adopted in the coming years. Once adopted, it will have a significant impact on the financial sector in the EU, requiring financial entities to enhance their digital operational resilience and comply with new regulatory requirements.
What is the purpose of DORA?
In detail
As seen above, the objective of DORA is clearly stated. To be more precise and to quote the text itself, we can read in its Recital 105, "achieve a high level of digital operational resilience for all regulated financial entities."
On paper I will say, "ok it’s good", but in reality the problems can appear from the beginning. That is to say that already, we must agree on the exact definition of "digital operational resilience". Because this notion is at first blurred, and in a second, may be interesting differently depending on the people who read it and try to apply it. Nevertheless, we are lucky, DORA kindly defines it as follows:
"The ability of a financial entity to develop, guarantee and reassess its operational integrity and reliability by directly or indirectly providing services provided by third-party ICT service providers, the full ICT capabilities necessary to ensure the security of the networks and information systems it uses, underpinning the continued provision of financial services and their quality, including in the event of disruptions" - DORA, Article 3(1)
The question is therefore initially "what really needs to be understood of this definition". "Defense is good, but resilience is even better!". This is what DORA is doing, financial entities (as well as their service providers/suppliers so as not to forget them) must no longer only defend themselves against the threat, but must also resist any other possible problems in preventing incidents.
To conclude on the objectives of this regulation, we can clearly see the positioning that aims to establish standardization on technical levels of resilience within a financial system to avoid incidents and better know how to manage them.
For when?
It is good to know that the implementation of the DORA regulation is on January 17, 2025. This is 24 months after its publication in the EU Official Journal. (source: Article 64)
So it’s all very well and good, you will tell me, but the question is how is this regulation implemented? Actually, on this point it is relatively clear. The DORA regulation divides these recommendations into 5 main pillars (knowing that the 5th pillar is optional in itself). It is at this time that I strongly recommend you to read the schema available above for the future, as we will base ourselves on it to address the different points. From now on, I will personally make "joujou" with the regulation!
Pillar 1 - ICT Risk Management
Governance and organization
The watchword for this point is relatively simple to understand. Clear governance structures with roles and responsibilities must be established.
So why and how? For the question of why, it is a question of pure organization. Take directly the case of an incident, how is the incident managed? By whom? And who are responsible? In reality, it is with the identification of clear roles within the organization and the creation of a clear governance structure that the incident can be more easily managed. It’s like on a walking boat when it’s attacked by a pirate ship, think about all these movies where they say "all at your post". Well, it is the same, except that of course, to go to his post, it is necessary to know what is the position we occupy, no? And we have leaders who take us with them, right?
And let’s not forget that an incident is technical and that it can impact on one side the internal employees which could go up to a certain general panic, possibly bring a certain atmosphere of fear on the side of the direction that possibly does not understand the level the difficulty of resolution of the impact. It is for this that having clear roles and a precise organization also allows better management of an incident. People know where to turn to ask the right questions and keep up to date on the consequences of the impact.
For the how, it depends more or less on your internal organization of your company. That is to say that technically, and for obvious reasons of simplicity, each "pole" should have "experts" dedicated to crisis management. This means people who know their job and their scope of application and who are capable to volunteer to help resolve the incident. To do this, we must manage to designate a set of "managers" capable of intervening on their core business and helping in case of incidents that affect them directly more or less.
Do not forget that in an organization of this kind, the organization must be clear to everyone and that obviously, training is done from time to time to keep the team active and test the skills of each.
In case of an incident, I strongly recommend that you communicate on the subject, even without detailing the incident, but explaining as clearly as possible the why of the how in order to possibly: sensitize in case of a cyber attack, to help others just understand to re-evaluate gravity, and also, have a written record.
ICT risk management framework
How to manage a risk? At first, I already want to answer you that you must be able to identify them. With this collection, you can put in place policies, procedures, protocols, and tools to better manage them.
Risk Identification
Well before starting to clearly identify what your risks are, I propose you to create before "families" of risks. As part of this explanation, I will identify 3, but the list can be evolutionary compared to your internal processes. So my risk families are:
- Cybersecurity risks
- Systems risks
- Real risks
The why of how now. Cybersecurity risks are all risks that are directly related to a cyber threat. That is to say all the threats that we can call "attack" on our system. The System risks are all risks directly related to the material itself, and finally, the real risks represent all risks that we cannot control, such as natural risks.
For more details, we can already identify some punchlines within these families.
Cybersecurity Risks
- Ransomware internally
- Phishing
- Malware
- Internal threat
- Data Leak
- Production Vulnerability
System Risks
- Hardware failure
- Network Issues
Real Risks
- Fire
- Natural disaster
Well obviously, which says risks, also says impacts. In order to have a visual of your risks, a table in a spreadsheet with colors that look like that (at least) may interest:
| Risks | Possible impact | Real similarity | Criticality | Price (range) |
|---|---|---|---|---|
| Ransomware | Employee PCs, Servers | Medium | Extreme | 10k - 2M |
| Phishing | Data Exfiltration | High | High | 20k - 4M |
| Malware | Data Exfiltration, Destruction | Low | High | 5k - 50k |
| Internal Threat | Sensitive Data Leak | Low | Medium | 50k - 500k |
| Data Leak | Financial, Reputational Loss | Medium | High | 1M - 5M |
| Production Vulnerability | Service Disruption | Low | Medium | 10k - 500k |
| Hardware Failure | Operational Disruption | High | Medium | 10k - 200k |
| Network Issues | Service Downtime | High | High | 20k - 1M |
| Fire | Complete Loss of Infrastructure | Low | Extreme | 100k - 10M |
| Natural Disaster | Complete Loss of Infrastructure | Low | Extreme | 500k - 50M |
Procedures
With these data, you can start to think about how to deal with the risks. In the table, I took a column called "possible impact". These are the impacts to be identified in the management of these risks. Of course, each incident will have a dedicated way to be managed, but it is possible to have a first rule that already can identify some classic behaviors.
| Risks | Possible impact | Possible behaviour |
|---|---|---|
| Ransomware | Employee PCs, Servers | Internal Information |
| Phishing | Data Exfiltration | Communication to public |
| Malware | Data Exfiltration, Destruction | Internal Information |
| Internal Threat | Sensitive Data Leak | Communication to public |
| Data Leak | Financial, Reputational Loss | Communication to public |
| Production Vulnerability | Service Disruption | Internal Information |
| Hardware Failure | Operational Disruption | Internal Information |
| Network Issues | Service Downtime | Internal Information |
| Fire | Complete Loss of Infrastructure | Communication to public |
| Natural Disaster | Complete Loss of Infrastructure | Communication to public |
With these behaviors, you can already clearly identify the necessary and clear process to follow. Then, a process (procedure) must be written internally and visible for everyone.
Protocols
As you can imagine, a procedure is good but it can only facilitate decision-making. This is why protocols exist. They must address, on a case-by-case basis, the entirety of access and possible derivations of an incident.
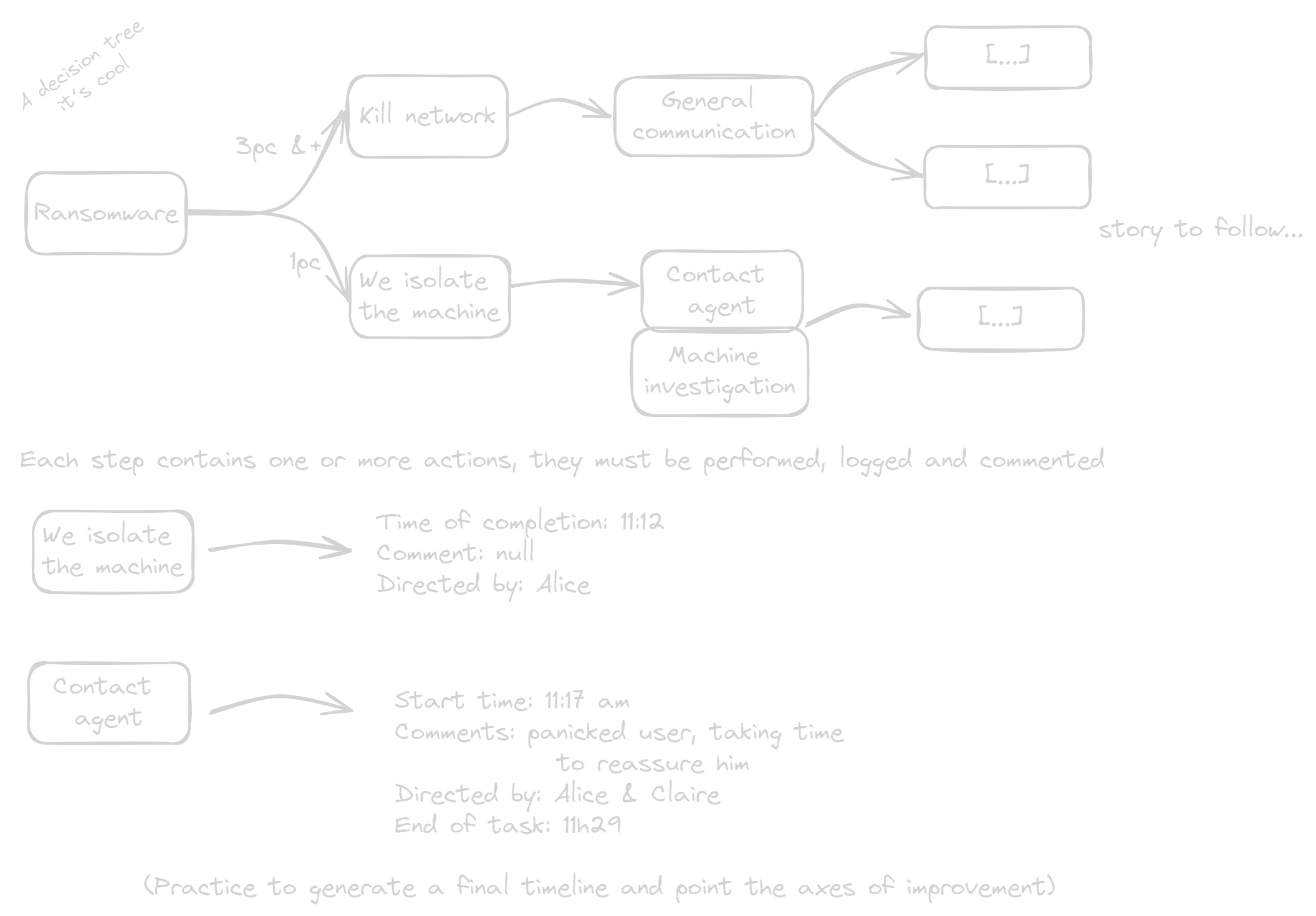
In essence, protocols are a sequence of detailed procedures that allow for a more complete framework.
Tools
Why are tools also an important point? It’s quite simple. In order to manage your incidents and implement your procedures and protocols, you need a set of tools. It is very important to list them and identify their exact uses.
For example, we can highlight the following collection of tools:
| Type | Description | Tools |
|---|---|---|
| SIEM | Threat Detection | sekoia.io, ELK, Wazuh |
| Anti Virus | Malware Detection | Windows Defender? |
| [...] | [...] | [...] |
The definition of the tools implemented depends on the company and on the major incident management accesses related to your previously identified risk matrix.
Protection and Prevention
For this point, we can summarize it as "Better to prevent than to cure." This part of DORA focuses on setting up prevention for the risks that have been identified beforehand. Once you have identified a collection of risks and explicitly described and set a level of criticality, you can then implement prevention measures.
So, how to do prevention? It’s very simple. First, it is necessary to address a specific risk, such as "vulnerability in production." For instance, if we are a victim of a PHP security breach on our website, the prevention might be obvious: updating a firewall to block this kind of attack when it is well configured.
To do this, you need to take your list of risks and list the solutions that can reduce the likelihood or impact of an incident. For organizational purposes, I recommend starting with reducing the likelihood and impact of 'critical' risks to provide a greater margin of maneuver and increase the security of your information system.
Detection
Having a well-developed risk management system is crucial, but it is useless if incidents are not detected. Therefore, it is important, even crucial, to have real-time detection tools for your services.
We can identify the following data sources:
| Name | Data Source |
|---|---|
| SIEM | - Agent on user PCs; - Agent on servers |
| Firewall | - Web threat detection |
| Anti Virus | - Known barrier blockage; - Basic analysis management (binary, mail, file) |
| Network Probe | - Network Anomaly Detection |
| System Monitoring | - System Fault Detection |
It is important to review the products annually to improve their characteristics and achieve a more detailed, precise, and oriented level of detection towards the incidents that affect you the most.
Response and Recovery
It is interesting to implement intervention plans with procedures and protocols, but it is equally important to establish recovery solutions. When setting up your incident management protocols, it is crucial to have a clear plan for returning to "normal" after an incident, as many solutions do not allow a return to normalcy.
Additionally, it is important to review (retex) the response and recovery procedures to better manage future similar incidents or identify areas for improvement.
Backups
This point is often addressed, re-addressed, and revisited, but it is worth a reminder: you need a plan to back up your data. Voila.
Pillar 2 - ICT-Related Incident Management, Classification, and Reporting
A - ICT Incident Management Framework
Establish a comprehensive framework for managing ICT incidents, including detection, response, recovery and learning.
Note: Detection, intervention and backup have already been addressed in Pillar 1.
Internal training
What do we do when we need to add a new person to the incident management team? First, it is necessary to give access to all existing resources on the subject. We can therefore begin with the following list:
| Document Name | Description |
|---|---|
| Risk lists | allows to have an overview of risks identifed internally and which must be monitored |
| Procedures | wiki with procedures to know its integration what are the procedures to respect |
| Protocols | in the same axis as the procedures, in case of incident management |
| Network scheme | in order to fully understand internal communication in order to have an overview of how links are made internally |
| Old incident report | to see the incidents that have already been dealt with and understand the application axes of the procedures & protocols |
| Backup plan | this helps to understand the procotoles of the last line of defense: restoration |
Full training
In order to test and challenge the procedures and protocols, it is important to be able to test them on a simulated environment (or even the production environment if it does not directly affect the business functions). It is important to start by testing the procedures in order of bulk in order to be "operational" as soon as possible
B - Incident Detection and Classification
Establish mechanisms for timely detection and accurate classification of ICT incidents. A short and comprehensive list of tools to be implemented:
SIEM
SIEM (Security Information and Event Management) provides security teams with a central place to collect, aggregate and analyze volumes of data across a company, allowing for efficient streamlining of security workflows.
SIEM systems play a critical role in incident detection and classification, which are essential components of the DORA. SIEM roles:
- Centralized Monitoring
- Correlation and Analysis
- Incident Detection
- Incident Classification
DORA’s Pillar 2 emphasizes the need for strong ICT risk management frameworks within financial entities. SIEM systems align with these requirements by providing:
-
Enhanced Detection Capabilities:
- Proactive Monitoring: Continuous monitoring and real-time analysis help in early detection of security incidents, minimizing potential damage and disruption.
- Comprehensive Coverage: By collecting data from various sources, SIEM systems ensure that no part of the IT infrastructure is left unmonitored, which is crucial for comprehensive risk management.
-
Efficient Incident Management:
- Rapid Response: SIEM systems enable faster incident response by providing actionable intelligence and alerting security teams promptly.
- Incident Documentation: SIEM systems keep detailed logs of all events and incidents, aiding in post-incident analysis and regulatory reporting, as required by DORA.
-
Regulatory Compliance:
- Audit Trails: SIEM systems maintain detailed audit trails of all monitored activities, which are essential for demonstrating compliance with regulatory requirements.
- Reporting Capabilities: SIEM solutions often include built-in reporting tools that can generate compliance reports aligned with DORA requirements, facilitating easier compliance management.
By providing centralized monitoring, real-time analysis, and efficient incident management capabilities, SIEM systems help us to enhance our operational resilience, detect and classify incidents promptly, and maintain regulatory compliance.
IDS
An IDS monitors network traffic and reports suspicious activity to response teams cyber security incidents and tools.
Their is the roles of an IDS:
- Network and Host Monitoring
- Signature-based Detection
- Anomaly-based Detection
- Alerting and Notification
- Incident Classification
IDS align with these requirements by providing:
-
Enhanced Detection Capabilities:
- Proactive Threat Detection: IDS systems offer proactive threat detection by continuously monitoring network and system activities for signs of malicious behavior.
- Comprehensive Coverage: IDS provide comprehensive monitoring of both network traffic and host activities, ensuring a broad coverage of potential attack vectors.
-
Efficient Incident Management:
- Timely Response: By generating immediate alerts for detected threats, IDS enable faster incident response, helping to contain and mitigate the impact of security incidents.
- Detailed Logging: IDS maintain detailed logs of all detected events and activities, supporting post-incident analysis and investigation.
-
Regulatory Compliance:
- Audit Trails: IDS systems create detailed audit trails of all monitored activities and detected incidents, essential for demonstrating compliance with DORA’s regulatory requirements.
- Reporting and Documentation: IDS can generate reports that document detected threats, incidents, and responses, facilitating easier regulatory reporting and compliance management.
IPS
An IPS is a network security tool (which can be a hardware device or software) that continuously monitors a network for malicious activity and takes action to prevent it, including reporting, blocking or abandonment, when it occurs.
Intrusion Prevention Systems (IPS) are vital in enhancing incident detection and classification, their roles are:
- Active Monitoring and Prevention
- Signature-based Detection
- Anomaly-based Detection
- Alerting and Response
- Incident Classification
IPS align with these requirements by providing:
-
Enhanced Detection and Prevention Capabilities:
- Proactive Threat Mitigation: IPS systems proactively detect and prevent threats in real-time, minimizing potential damage and operational disruptions.
- Comprehensive Protection: IPS offers comprehensive protection by monitoring both network and host activities, ensuring broad coverage of potential attack vectors.
-
Efficient Incident Management:
- Rapid Response: IPS systems enable rapid response to detected threats by automatically blocking or mitigating them, reducing the time window for potential damage.
- Detailed Logging: Maintain detailed logs of all detected and prevented incidents, supporting post-incident analysis and regulatory reporting.
-
Regulatory Compliance:
- Audit Trails: IPS systems create comprehensive audit trails of all monitored activities and prevented incidents, essential for demonstrating compliance with DORA’s regulatory requirements.
- Reporting and Documentation: IPS can generate detailed reports documenting detected and prevented threats, aiding in regulatory reporting and compliance management.
System Health
A monitoring system for infrastructure activities can detect anomalies on systems and prevent possible failures
System health monitoring tools, such as Grafana, play a significant role in incident detection and classification. These tools are essential for maintaining the operational resilience of financial entities by providing real-time visibility into the health and performance of IT infrastructure, enabling early detection and classification of potential issues.
What does a monitoring tools need to do:
- Real-time Monitoring
- Anomaly Detection
- Visualization and Correlation
- Alerting and Notification
- Incident Classification
System health monitoring tools align with these requirements by providing:
-
Enhanced Detection Capabilities:
- Proactive Monitoring: Continuous real-time monitoring helps in early detection of potential issues before they escalate into major incidents, minimizing operational disruptions.
- Comprehensive Coverage: Monitoring tools provide comprehensive visibility into the health of various components of the IT infrastructure, ensuring no critical aspect is overlooked.
-
Efficient Incident Management:
- Rapid Response: Real-time alerts and detailed contextual information enable faster response to detected issues, helping to mitigate potential impacts promptly.
- Historical Data Analysis: Logs and historical data support post-incident analysis, helping to understand the root causes and improve future incident response strategies.
-
Regulatory Compliance:
- Audit Trails: Monitoring tools maintain detailed logs of all monitored metrics and detected incidents, essential for demonstrating compliance with DORA’s regulatory requirements.
- Reporting and Documentation: Generate comprehensive reports on system health and incident management, facilitating easier regulatory reporting and compliance management.
By providing real-time visibility, anomaly detection, detailed alerts, and incident classification, these tools help us to monitor activities.
C - Incident Detection and Classification
It is important to have a clear process for detecting and classifying incidents. This includes establishing criteria for incident classification, such as severity, impact, and urgency, and ensuring that incidents are promptly reported and escalated to the appropriate response teams.
D - Learning and Continuous Improvement
It is extremely important to review incidents at least once a year. In order to do complete incident reviews, it is important to have the following resources:
| Ressource | Why ? |
|---|---|
| Company objectives | in order to identify the major axes of evolution of the company and readapt the risks to the business needs |
| Retex of incidents | allows you to see past incidents and evaluate which key points could be improved |
| Areas for improvement | the list of possible areas of improvement that have been mentioned by crisis managers past |
| Cyber trends | in order to possibly change the likelihood of a risk or prepare for new types of attack |
| New technology | Can new security technology exist on the market? |
E - Incident escalation procedure
There’s not much to say. The more complex or serious the incident seems, the more it must be escalated, and in the other direction, each level of analysis must accompany less experienced analysts in order to have an evolution of skills.
Pillar 3 - Digital Operation Resilience Testing
A - Testing Framework
Establish a comprehensive framework for testing the digital operational resilience of financial entities, including the development of test scenarios, testing methodologies, and reporting mechanisms.
As part of a training program, it is important to have a clear framework for testing the digital operational resilience of financial entities. This includes the development of test scenarios, testing methodologies, and reporting mechanisms to ensure that financial entities are adequately prepared to respond to and recover from incidents.
We also need to setup a simulation system identical to target systems in order to test the resilience of the system.
First we can like, integrate it into the CI/CD chain to ensure that all application that will be deployed are a minimum secure & can be resilient.
What is CICD ?
CI/CD stands for Continuous Integration and Continuous Deployment (or Continuous Delivery). It is a set of practices and tools used in modern software development to ensure that code changes are integrated, tested, and delivered to production environments frequently and reliably.
-
Continuous Integration (CI):
- Integration of Code: Developers frequently merge their code changes into a shared repository, often multiple times a day.
- Automated Testing: Each integration triggers an automated build and testing process to identify any issues early.
- Early Bug Detection: CI helps in catching bugs and integration issues early in the development cycle.
-
Continuous Deployment/Delivery (CD):
- Continuous Deployment: Automatically deploys every change that passes all stages of the production pipeline to customers without manual intervention.
- Continuous Delivery: Ensures that code is always in a deployable state but requires manual approval to deploy to production.
- Automation: Automates the release process, reducing manual errors and speeding up the time to market.
Overall, CI/CD aims to improve software quality, accelerate the release process, and enhance collaboration among development teams.
Why include Cybersecurity in the process ?
Integrating cybersecurity practices into the CI/CD pipeline is essential for ensuring that applications are secure and resilient from the start. By incorporating security checks and testing into the development process, organizations can identify and address vulnerabilities early, reducing the risk of security incidents and data breaches.
Key benefits of integrating cybersecurity into the CI/CD pipeline include:
Including cybersecurity tests and resilience testing in the CI/CD process is crucial for several reasons:
Cybersecurity Tests:
-
Early Detection of Vulnerabilities:
- Proactive Identification: Automated security tests help detect vulnerabilities early in the development cycle, reducing the risk of exploits in production.
- Cost-Effective: Fixing security issues earlier in the process is often less costly than addressing them after deployment.
-
Compliance:
- Regulatory Requirements: Many industries have strict regulations requiring regular security testing. Integrating these tests helps ensure compliance with laws and standards.
- Audit Preparedness: Continuous security testing ensures that the system is always ready for security audits.
-
Risk Mitigation:
- Threat Prevention: Regular security tests help identify and mitigate potential threats before they can be exploited by malicious actors.
- Trust and Reputation: Ensuring the security of applications helps maintain the trust of users and protects the organization's reputation.
Resilience Testing:
-
System Reliability:
- Fault Tolerance: Resilience testing ensures that the system can handle failures and continue operating, enhancing overall reliability.
- Recovery Capabilities: It verifies that systems can recover quickly from failures, minimizing downtime.
-
Performance Under Stress:
- Load Handling: Testing the system under various stress conditions ensures it can handle high loads and peak traffic without degrading performance.
- Bottleneck Identification: Identifying performance bottlenecks helps in optimizing the system for better performance and user experience.
-
Disaster Preparedness:
- Contingency Planning: Resilience testing helps in developing and validating disaster recovery plans, ensuring the system can recover from catastrophic failures.
- Business Continuity: Ensures that critical services remain available during unexpected disruptions, maintaining business continuity.
B - Vulnerability Assessment
Establish a comprehensive framework for conducting vulnerability assessments, including identifying vulnerabilities, assessing their impact, and prioritizing remediation efforts. In the case of DORA, we can instore a vulnerability assessment program that includes the following steps:
-
Identifying Vulnerabilities:
- Automated Scanning: Use automated tools to scan the network, applications, and systems for known vulnerabilities.
- Manual Testing: Conduct manual testing to identify complex vulnerabilities that automated tools may miss.
-
Assessing Impact:
- Risk Analysis: Evaluate the potential impact of each vulnerability on the organization's operations, data, and reputation.
- Prioritization: Prioritize vulnerabilities based on their severity, likelihood of exploitation, and potential impact.
-
Remediation Efforts:
- Patch Management: Develop a patch management process to address identified vulnerabilities promptly.
- Security Controls: Implement security controls to mitigate risks associated with unpatched vulnerabilities.
-
Continuous Monitoring:
- Ongoing Assessment: Continuously monitor the network and systems for new vulnerabilities and emerging threats.
- Regular Updates: Keep security tools and systems up to date to ensure effective vulnerability assessment.
Software
There is multiple short list of software based on the type of vulnerability assessment you want to do:
1. Identifying Vulnerabilities
Automated Scanning
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Nessus | Comprehensive vulnerability scanning and assessment tool. | Nessus | Continuous Code Improvement, Measurement |
| OpenVAS | Open-source vulnerability scanner with extensive plugins. | OpenVAS | Continuous Code Improvement |
| Qualys | Cloud-based platform for vulnerability management. | Qualys | Continuous Code Improvement, Measurement |
Manual Testing
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Burp Suite | Web vulnerability scanner and penetration testing toolkit. | Burp Suite | Continuous Code Improvement |
| Metasploit | Exploitation framework used for penetration testing. | Metasploit | Continuous Code Improvement |
| OWASP ZAP | Open-source web application security scanner. | OWASP ZAP | Continuous Code Improvement |
2. Assessing Impact
Risk Analysis
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| RiskWatch | Risk management software for evaluating potential impacts. | RiskWatch | Measurement |
| RSA Archer | Platform for integrated risk management and compliance. | RSA Archer | Measurement, Continuous Feedback |
| Skybox Security | Provides risk assessment and exposure analysis. | Skybox | Measurement |
Prioritization
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Kenna Security | Prioritizes vulnerabilities based on risk and potential impact. | Kenna Security | Continuous Code Improvement, Measurement |
| Nexpose | Real-time vulnerability management and prioritization. | Nexpose | Continuous Code Improvement |
| Tenable.io | Cloud-based platform for prioritizing and remediating vulnerabilities. | Tenable.io | Continuous Code Improvement, Measurement |
3. Remediation Efforts
Patch Management
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| ManageEngine | Patch management software for automating patch deployment. | ManageEngine | Continuous Code Improvement, Measurement |
| Ivanti | Comprehensive patch management and endpoint security. | Ivanti | Continuous Code Improvement, Measurement |
| SolarWinds | Patch management and IT service management solutions. | SolarWinds | Continuous Code Improvement |
Security Controls
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Cisco Umbrella | Cloud security platform providing DNS-layer security. | Cisco Umbrella | Continuous Code Improvement, Measurement |
| Palo Alto Networks | Network security solutions with advanced threat prevention. | Palo Alto Networks | Continuous Code Improvement, Measurement |
| CrowdStrike Falcon | Endpoint protection with advanced threat intelligence. | CrowdStrike | Continuous Code Improvement, Measurement |
4. Continuous Monitoring
Ongoing Assessment
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Splunk | Data analytics platform for security monitoring and incident response. | Splunk | Continuous Feedback, Measurement |
| Nagios | Open-source monitoring for network and system health. | Nagios | Continuous Feedback, Measurement |
| AlienVault USM | Unified security management with continuous threat detection. | AlienVault | Continuous Feedback, Measurement |
Regular Updates
| Software | Description | Link | DORA Requirement |
|---|---|---|---|
| Chef | Automation platform for infrastructure as code and continuous delivery. | Chef | Continuous Code Improvement, Continuous Delivery |
| Puppet | Configuration management tool for automating software delivery. | Puppet | Continuous Code Improvement, Continuous Delivery |
| Ansible | Open-source automation tool for IT configuration and management. | Ansible | Continuous Code Improvement, Continuous Delivery |
C - Penetration Testing
Simulate real-world cyber attacks to identify vulnerabilities and assess the effectiveness of security controls.
In this step, you just need to use the list available in the Vulnerability Assessment section and use them to simulate real-world cyber attacks to identify vulnerabilities and assess the effectiveness of security controls.
D - Advanced threat led penetration testing (TLPT)
Conduct thorough penetration testing based on advanced threat scenarios to identify vulnerabilities and assess the effectiveness of security controls.
In this step, you just need to use the list available in the Vulnerability Assessment section and use them to simulate real-world cyber attacks to identify vulnerabilities and assess the effectiveness of security controls.
Call external experts to help you in this process.
E - Ensure resilience of critical systems
So first, we can start by define "What is Resilience?".
Resilience in the context of critical systems refers to the ability of a system to continue functioning properly in the face of various forms of disruptions. This can include hardware failures, software bugs, cyber-attacks, natural disasters, and human errors. A resilient system can withstand these disruptions, maintain essential functions, and recover quickly to normal operations.
So in this case, ensuring resilience is crucial for critical systems as it minimizes downtime, prevents data loss, and maintains service availability and integrity. This is particularly important in sectors like finance, healthcare, telecommunications, and energy, where disruptions can have severe consequences.
Strategies for Ensuring Resilience
-
Redundancy
- Hardware Redundancy: Duplicate critical hardware components (servers, storage devices, network equipment) to prevent single points of failure.
- Software Redundancy: Use failover mechanisms, load balancing, and clustering to ensure continuous software operations.
-
Regular Backups
- Implement automated backup procedures to regularly save critical data.
- Store backups in multiple locations, including off-site or in the cloud, to protect against physical disasters.
-
Disaster Recovery Planning
- Develop and maintain a comprehensive disaster recovery plan outlining procedures for responding to various types of disruptions.
- Conduct regular drills and simulations to test the effectiveness of the disaster recovery plan.
-
Monitoring and Alerts
- Implement continuous monitoring of system performance and health.
- Set up automated alerts for abnormal activities or performance degradation.
-
Cybersecurity Measures
- Deploy robust security measures, including firewalls, intrusion detection/prevention systems (IDS/IPS), and anti-malware tools.
- Regularly update software and security patches to protect against vulnerabilities.
-
System Hardening
- Apply best practices for system configuration to reduce vulnerabilities.
- Disable unnecessary services and features, enforce strong authentication, and follow the principle of least privilege.
-
Diverse System Architectures
- Use a mix of different technologies and platforms to reduce the risk of widespread failure due to a single vulnerability.
- Implement multi-cloud or hybrid cloud strategies to avoid dependency on a single service provider.
Testing and Ensuring Resilience
-
Risk Assessment
- Conduct regular risk assessments to identify potential threats and vulnerabilities.
- Prioritize risks based on their impact and likelihood.
-
Stress Testing
- Perform stress tests to evaluate system performance under extreme conditions.
- Identify bottlenecks and areas for improvement.
-
Penetration Testing
- Engage in regular penetration testing to identify and address security vulnerabilities.
- Use both internal teams and external experts for a comprehensive assessment.
-
Chaos Engineering
- Implement chaos engineering practices by intentionally introducing failures into the system to test its resilience.
- Use tools like Chaos Monkey to simulate failures and observe system behavior.
-
Failover Testing
- Regularly test failover mechanisms to ensure they function correctly during an actual disruption.
- Simulate various failure scenarios to verify system continuity.
-
Backup and Restore Testing
- Periodically test backup procedures to ensure data can be restored successfully.
- Validate the integrity and completeness of backup data.
-
Incident Response Drills
- Conduct incident response drills to ensure teams are prepared to handle real-life incidents.
- Review and improve incident response plans based on drill outcomes.
-
Review and Update Policies
- Continuously review and update resilience policies and procedures.
- Stay informed about emerging threats and evolving best practices.
Ensuring the resilience of critical systems requires a proactive and comprehensive approach that combines technical measures, testing, and continuous improvement. By implementing resilience strategies and conducting regular assessments, organizations can minimize the impact of disruptions and maintain operational continuity.